
GraphQL is a query language for APIs, and a server-side runtime for executing queries using a type system defined for data.
Introduction of RESTful APIs
In a typical software project, a RESTful API (Representational State Transfer Application Programming Interface) serves as a standardized way for different software components to communicate with each other over the internet. It uses standard HTTP methods (GET, POST, PUT, DELETE) and is based on a client-server, stateless architecture.
It is widely used in Client-Server Communication (Web and Mobile applications), Microservices Architecture, and Third-Party Integrations. Data is most commonly exchanged in JSON format due to its lightweight nature and ease of parsing in most programming languages.
Disadvantages of RESTful APIs
Despite its popularity and simplicity, RESTful APIs have several disadvantages:
1. Over-fetching
An endpoint often returns a fixed set of data. The client may receive more information than it actually needs, which wastes bandwidth and can slow down the application. For example, a mobile app might only need a user's name and email from the /api/users/{id}endpoint, but the API returns the full user object, including city, email, and phone number.
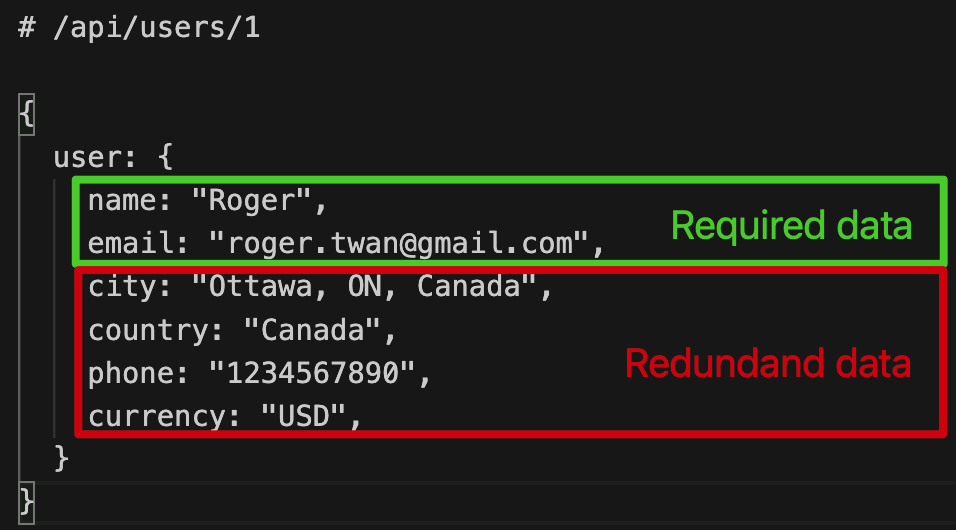
2. Under-fetching
The opposite of over-fetching, the client doesn't get enough information from a single request and must make multiple API calls to fetch all the required data. For example, to display a blog post with its author's details and comments, the client might need to make three requests:
- post data:
/api/posts/1 - user data:
/api/users/1 - comment data:
/api/posts/1/commentsThis increases latency and complexity.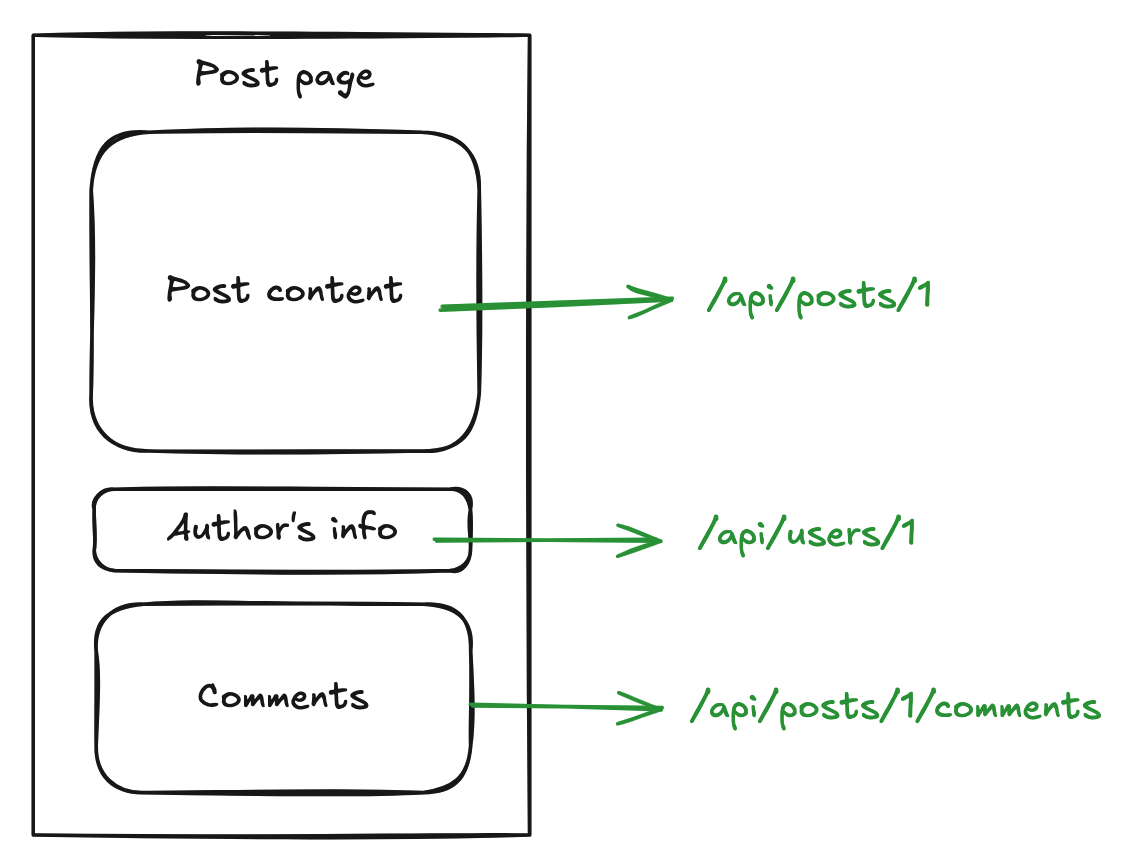
3. Multiple Round Trip
Related to under-fetching, complex user interfaces often require data from multiple resources. This leads to a chain of HTTP requests, where each request adds latency. This can result in a poor user experience, especially on slow mobile networks.
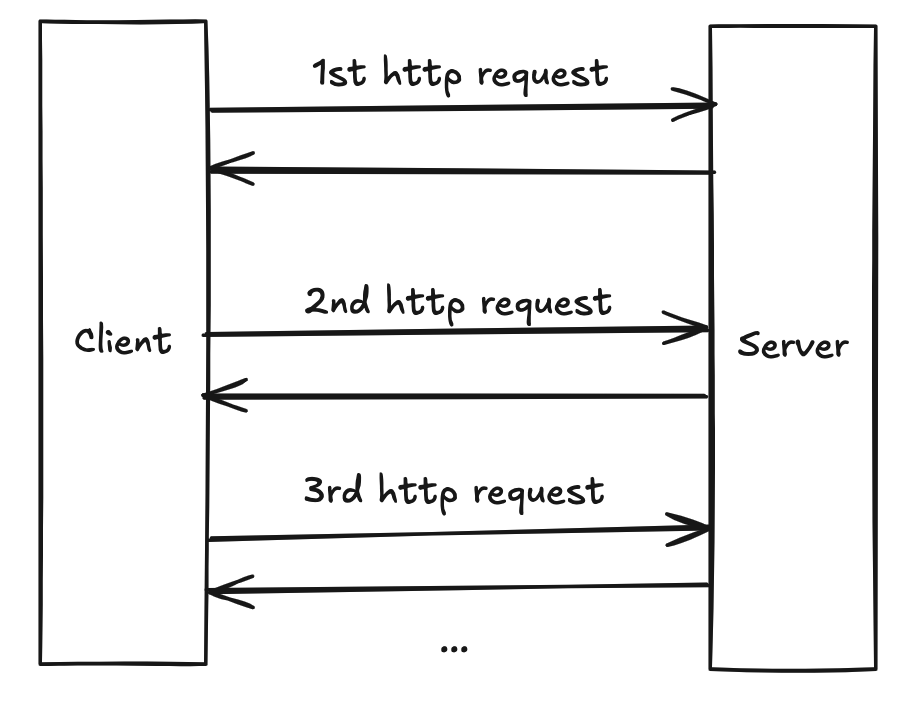
4. Versioning Challenges
As an application evolves, its API needs to change. Managing these changes without breaking existing client applications is difficult. A common approach is to version the API (e.g., /api/v1/products, /api/v2/products), but this can lead to maintaining multiple versions of the code, increasing complexity and maintenance overhead.
5. Lack of a Strong Type System
REST itself doesn't enforce a strict contract or schema for the API. While tools like Swagger can be used to document the API structure, it's an add-on, not a core part of the architecture. This can lead to miscommunication between frontend and backend teams about data types and structures. The backend team may also spend extra time maintaining the documentation.
How GraphQL Solves API Challenges
With GraphQL, the client sends a precise query detailing the exact fields and structure it needs. The backend's role is no longer to build custom endpoints for each view, but to provide a single, powerful schema that describes all possible data.
1. Fetch exactly what the client needs
// Request what the client needs
{
user(id: "1") {
name,
email
}
}
// Get predictable results, no more and no less
{
"user": {
"name": "Roger",
"email": "roger.twan@gmail.com"
}
}
2. Fetch all data in a single request
We can fetch all resources in a single HTTP request, decreasing the latency.
{
post(id: "1") {
title
content
author {
id
name
}
comments {
id
text
author {
name
}
}
}
}
3. API without versions
We can add new fields to a type any time without impacting existing requests because the client only fetches what they need. We can also add a directive to a field to avoid future use.
type User {
// Add fullName field instead of name
fullName: String
name: String @deprecated // add @deprecated directive to avoid future use
email: String
city: String
country: String
phone: String
}
4. Strong type system
GraphQL addresses the lack of a strong type system in REST by making a strongly-typed Schema the absolute core of its architecture.
type User {
id: ID!
email: String!
city: String
country: String
phone: String
}
type Post {
id: ID!
title: String!
author: User!
}
System Architecture Design
In a traditional MVC design pattern with REST, each Controller is responsible for a specific URL and HTTP method. However, GraphQL has only one entry (typically /graphql), where the Schema and Resolvers assume much of the responsibility that would normally fall to Controllers.
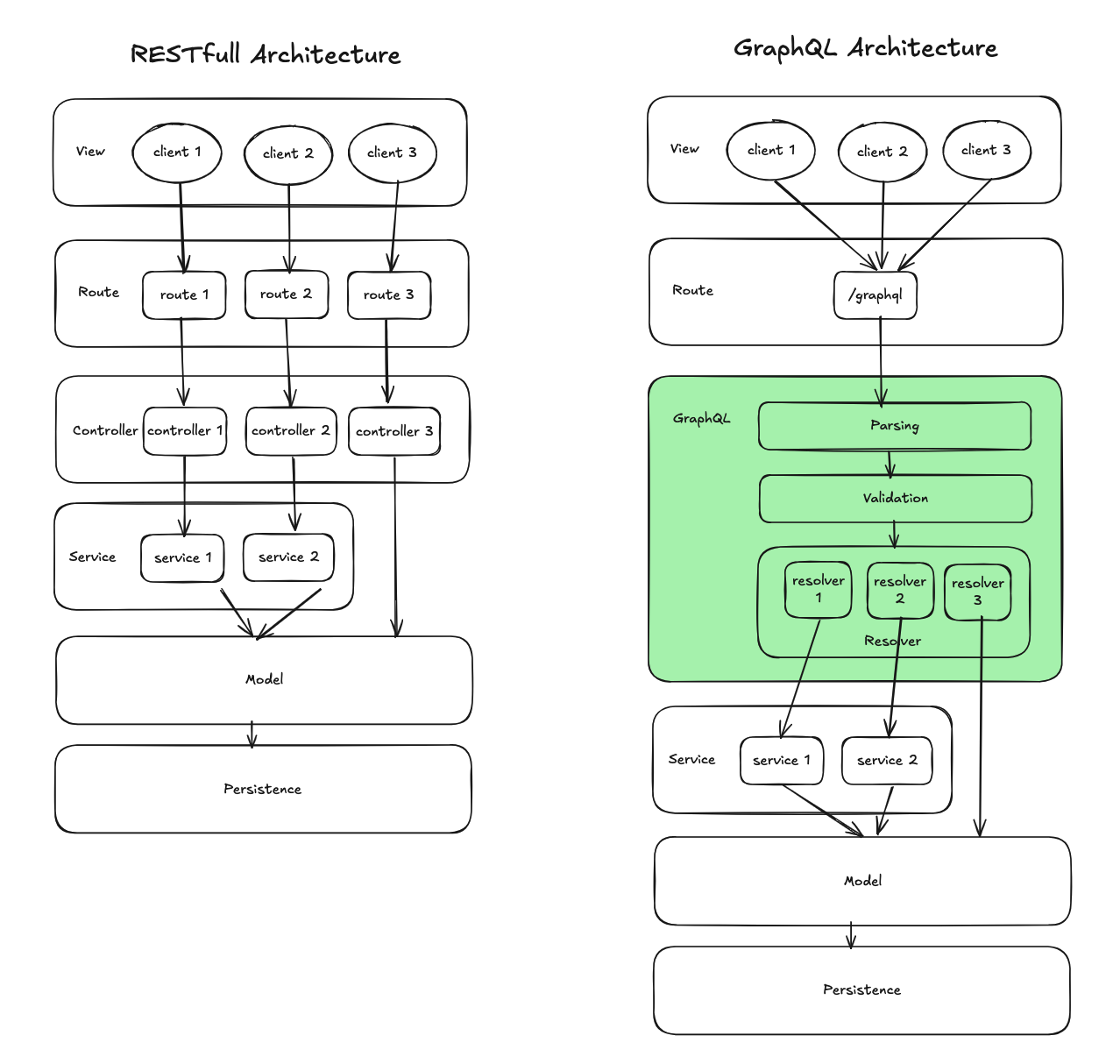 We can also attach middleware before or after the
We can also attach middleware before or after the /graphql route to handle authentication and limit requests.
Performance Monitoring
Monitoring GraphQL performance is a bit trickier than REST, because REST has clear, fixed endpoints (/users, /orders), while GraphQL has a single endpoint (/graphql) and the actual endpoint is the query structure. So to effectively monitor GraphQL, we need to go deeper:
- Operation name: Track which queries or mutations are being executed, as this is the closest equivalent to REST endpoints.
- Resolver-level performance: Measure the execution time of individual resolvers, since a single query may fan out into multiple resolvers. This helps pinpoint slow fields or nested data fetches.
- Query complexity: Monitor the depth and cost of incoming queries to detect abusive or inefficient requests.
- Error rates: Instead of only tracking request-level errors, capture which fields or resolvers fail most often.
- Throughput and latency: Aggregate metrics across all operations to understand overall API performance. This approach allows teams to achieve the same level of visibility as REST. Fortunately, there are many APM/Observability tools such as Apollo Studio, Grafana with Prometheus, and OpenTelemetry. These tools can automatically collect and visualize these metrics.
Schema Documentation
Just like REST teams rely on Swagger/OpenAPI to understand available endpoints, frontend developers and other cross-functional teams also need a clear reference for GraphQL. Since GraphQL exposes a schema instead of fixed endpoints, we need to provide schema documentation so teams know which queries, mutations, and fields are available, along with their types and relationships.
1. Introspection
This is the core feature that powers everything else. A GraphQL server has a built-in, standardized way to describe itself. The frontend can send a special query (an "introspection query") to the GraphQL endpoint, and the server will respond with its entire schema: all the types, fields, queries, mutations, and their descriptions.
2. Developer tools
Tools like GraphiQL, GraphQL playground provide an immediate, always-up-to-date view for any developer interacting with the API.
3. Static schema files
We can use a command-line tool to fetch the schema from the development server and save it. The two most common file formats are schema.graphql (human-readable SDL) or schema.json (the result of the introspection query).
4. Code generation
By having the static schema file, we can automatically generate TypeScript (or other language) types that perfectly match the API using GraphQL Code Generator
The best practice professional workflow:
- The backend team develops the GraphQL API.
- During development, the frontend team uses GraphQL Playground to explore and write queries.
- As part of the CI/CD pipeline (or manually), the frontend project runs a script to download the latest schema into a
schema.graphqlfile. - The frontend project uses GraphQL Code Generator to automatically create TypeScript types from that schema and the queries written by the team.
Side Effects and Solutions
Despite its many advantages, GraphQL also comes with certain drawbacks.
1. Caching
- In REST, each endpoint can leverage HTTP caching (ETag, Cache-Control)
- In GraphQL, with only one endpoint, responses vary based on query parameters, making HTTP caching less effective
Solution: rely on client-side caching (e.g., Apollo Cache) or server-side caching strategies
2. Increased frontend complexity
- Frontend must understand the GraphQL schema to build queries
- If the schema changes frequently, queries and types in the frontend must be updated accordingly
Solution: use graphql-code-generator to generate types and hooks, leverage IDE autocomplete to reduce errors
3. Complex queries may impact performance
- Deeply nested queries or fetching too many fields → higher database load and CPU usage
- A single GraphQL query can fetch deeply nested data → potential for abuse
- N+1 query problem: without DataLoader or batch fetching, backend performance can degrade severely
Solution: pagination, field restrictions, query depth limits, batch fetching
4. Adoption cost
- For small APIs or straightforward CRUD scenarios, the cost of adopting GraphQL may outweigh the benefits
- Extra learning curve and toolchain required (Apollo, Codegen, DataLoader, etc.)
Summary of Drawbacks
| Drawback | Impact | Solution |
|---|---|---|
| Caching difficulties | HTTP caching less effective | Client-side or server-side caching |
| Frontend complexity | Queries harder to construct vs REST | Codegen, type-safety, IDE support |
| Complec query performance | Higher CPU load, DB pressure | Pagination, depth limits, DtaLoader |
| Adoption cost | Higher dev complexity for small APIs | Use REST + GraphQL hybrid |
Conclusion
GraphQL’s strengths include flexible querying, fewer network requests, and strong type safety. Its main drawbacks are related to performance management, caching, security, and the steep learning curve.
For small APIs or MVP projects, the benefits of adopting GraphQL are often limited. The additional learning curve and optimization requirements may introduce unnecessary overhead, while REST is usually sufficient for such use cases.
In contrast, for large-scale APIs, where the data model is complex, queries are diverse, and the user base is large, GraphQL can provide significant advantages in terms of front-end request optimization, data aggregation, and type safety.
As a best practice, a hybrid approach is often recommended: use REST for responsibilities such as user authentication, while leveraging GraphQL for flexible and efficient data interactions once authentication is complete.
Choosing Between RESTful and GraphQL
| Dimension | Small-Scale API Project | Large-Scale API Project |
|---|---|---|
| Feature Scope | Simple features, a few basic CRUD endpoints | Complex features, multiple modules, many aggregation endpoints |
| Number of APIs | Few (a handful to dozens) | Many (tens to hundreds) |
| Data Volume | Small (hundreds to tens of thousands of records) | Large (millions to billions of records) |
| Data Structure | Simple, few tables, minimal relationships | Complex, multiple tables, multi-level relationships |
| User Load / Concurrency | Low, minimal server pressure | High, requires performance optimization and scalability |
| Access Control | Simple or none | Multi-role, multi-layer permissions requiring fine-grained management |
| Development Cost | Fast development, low learning curve | Higher development cost, complex architecture, requires team collaboration |
| Maintenance Cost | Simple, easy to manage | Higher, requires comprehensive monitoring, testing, and optimization strategies |
| Best Fit | REST is sufficient; GraphQL optional with limited benefits | GraphQL or a REST+GraphQL hybrid to optimize requests and data aggregation |